
Transparently Routing / Proxying Information
I was required to utilize a transparent proxy. The general idea was to follow a diagram as the one here:
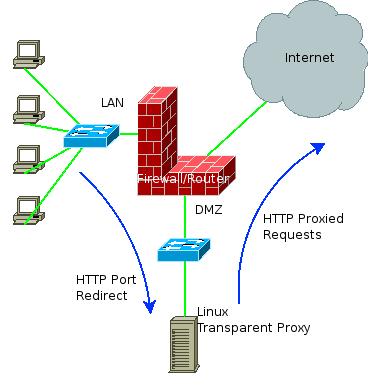
The company did not want any information (http, https, ftp, whatever) to pass directly through the firewall from the internal network to the external network. If we can move it all via some sort of proxy, the general idea says, the added security is well worth it.
Getting an initial configuration to work is rather simple. For port 80 (HTTP), all need not do more than install squid with transparent directives included (can be found here, for example, and on dozens of other web sites), and make sure the router redirects all outbound HTTP traffic to the Linux proxy.
It worked like a charm. Few minor tweeks, and caching was done well.
It didn’t work when it came to other protocols. It appreas Squid cannot transparently redirect (I did not expect it to actually cache the information) SSL requests. The whole idea of SSL is to prevent the possibility of “A-Man-in-the-Middle” attack, so Squid cannot be part of the point-to-point communication, unless directed to do so by the browser, with the CONNECT command. This command can be assigned ONLY if the client is aware of the fact that there is a proxy on the way, aka, configured to use it, which is in contrast to the whole idea of Transparent Proxy.
When it failed, I’ve came up with the next idea – let the Linux machine route onwards the forwarded packets, by acting as a self-sustained NAT server. If it can translate all requests as comming from it, I will be able to redirect all traffic through it. It did not work, and working hard into IPTables chains, and adding logging (iptables -t nat -I PREROUTING -j LOG –log-prefix “PRERouting: “) into it, I’ve discovered that although the PREROUTING chain accepted the packets, they never reached the FORWARD or POSTROUTING chains…
The general conclusion was that the packets were destinated to the Linux machine. The Firewall/Router has redirected all packets to the Linux server not by altering the routing table to point at the Linux server as the next hop, but by altering the destination of the packets themselves. It meant that all redirected packets were to go to the Linux machine.
Why did HTTP succeed in passing the transparent proxy? Because HTTP packets contain the target name (web address) in their data, and not only in their headers. This allows for “Name based shared hosting”, and thus the transparent proxy can actually exist.
There is no such luck with other protocols, I’m afraid.
The solution in this case can be achieved via few methods:
1. Use non-transparent proxy. Set the clients to use it via some script, which will enable them to avoid using it when outside the company. Combined with transparent HTTP proxy, it can block unwanted access.
2. Use stateful inspection on any allowed outbound packets, except HTTP, which will be redirected to the proxy server transparently.
3. Set the Linux machine in the direct path outside, as an additional line of defence.
4. If the firewall/Router is capable of it, set a protocol-based routing. If you only route differently packets outbound for some port, you do not rewrite the packet destination.
I tend to chose option 1, as it allows for access to work silently when using HTTP, and prevents unconfigured clients from accessing disallowed ports. Such a set of rules could look something like (the proxy listens on port 80):
1. From *IN* to *LINUX* outbound to port 80, ALLOW
2. From *IN* to *INTERNET* outbound to port 80 REDIRECT to Linux:80
3. From *IN* to *INTERNET* DENY
Clients with defined proxy settings will work just alright. Clients with undefined proxy settings, will not be able to access HTTPS, FTP, etc, but will still be able to browse the regular web.
In all these cases, control over the allowed URLs and destinations is in the hands of the local IT team.

What will happend with users that working with FTP but not with browser (from command line) how could they archive the proxy detail?